
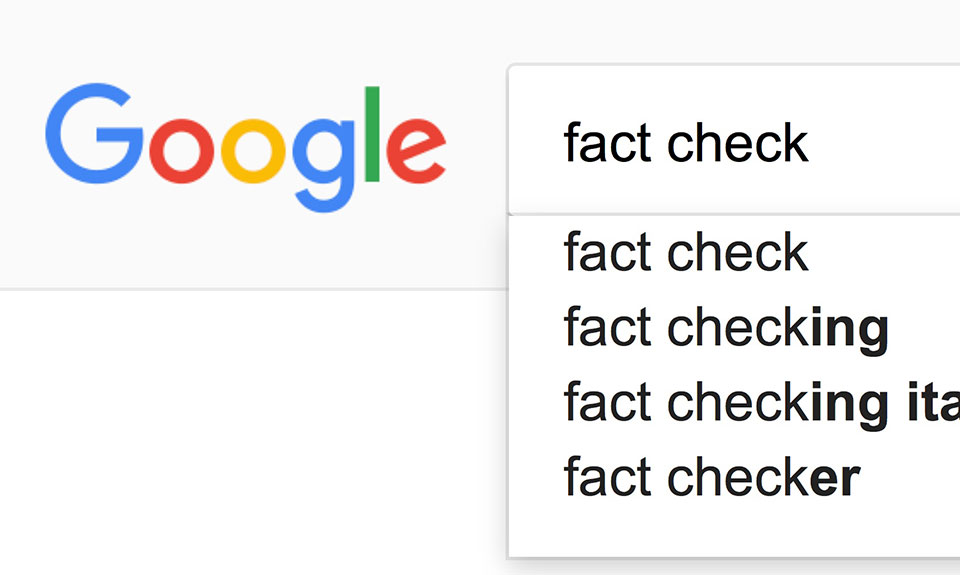
L’etichetta Fact Check è da qualche settimana disponibile in tutti i paesi nella ricerca Google e in Google News
Cosa sia e come sia stata sviluppata lo spiega la stessa Google.
“Google è stata creata con l’obiettivo di aiutare gli utenti a trovare informazioni utili, offrendo visibilità ai contenuti che gli editori creano.
Tuttavia, con migliaia di nuovi articoli pubblicati online ogni minuto di ogni giorno, la quantità di contenuti con cui si confrontano gli utenti può risultare eccessiva. E purtroppo, non tutti questi contenuti sono aderenti ai fatti o veri, rendendo così difficile per i lettori distinguere i fatti da ciò che è falso.
L’etichetta “Fact Check” in Google News consente di identificare in modo più immediato gli articoli di verifica dei fatti, ed è ora disponibile ovunque ed estesa al motore di ricerca, a livello globale e in tutte le lingue.
Quando viene effettuata una ricerca su Google che restituisce un risultato che contiene la verifica dei fatti di uno o più affermazioni pubbliche, questa informazione verrà chiaramente visualizzata nella pagina dei risultati di ricerca. Lo snippet mostrerà informazioni sulla dichiarazione verificata, da chi è stata fatta e se una fonte ha verificato quella particolare dichiarazione.
Queste informazioni non sono disponibili per qualsiasi risultato e potrebbero esserci pagine di risultati di ricerca in cui diverse fonti hanno verificato la stessa affermazione raggiungendo però conclusioni diverse.
Queste verifiche dei fatti naturalmente non sono effettuate da Google e potremmo anche non essere d’accordo con i risultati, proprio come diversi articoli di fact checking potrebbero essere in disaccordo tra loro, tuttavia Google ritiene che sia utile per le persone capire il grado di consenso attorno a un argomento e avere informazioni chiare su quali fonti concordano.
Per poter usufruire di questa etichetta, gli editori devono utilizzare il markup ClaimReview di Schema.org sulle pagine nelle quali effettuano il fact checking di dichiarazioni pubbliche o usare il widget Share the Facts sviluppato dal Duke University Reporters Lab e Jigsaw.
Solo gli editori che sono algoritmicamente determinati come fonte autorevole di informazioni si qualificheranno per essere inclusi. Infine, i contenuti dovranno rispettare le norme generali che si applicano a tutti i tag di dati strutturati e ai criteri di Google News Publisher per il fact checking.
Tutto questo può essere a prima vista molto positivo, proprio se si pensa a quante fake news quotidianamente vengono pubblicate, con un grave pregiudizio per l’informazione individuale e collettiva.
Ma quella messa in campo da Google non è un’iniziativa squisitamente etica e filantropica.
Le fake-news sono uno strumento per attrarre traffico e utenti su siti tecnicamente e contenutisticamente irrilevanti. Questo “devisa” anche la webreputation, distorce il mercato pubblicitario, sposta inserzionisti che invece dovrebbero essere premiati (sempre dagli algoritmi) in base alla qualità dei contenuti, alla loro autenticità ed originalità.
Per questo Google – e gli altri big del web – si sono mossi con altrettanti algoritmi per evitare (o cercare i limitare) distorsioni di mercato che possano mettere il discussione le leadership dei colossi della pubblicità online, su cui si reggono i loro fatturati ma anche quelli degli editori online.
Tempo fa accadde che Umberto Eco volle correggere alcune informazioni sulla sua bio apparsa su wikipedia. Gli venne risposto che le modifiche proposte erano “con fonti irrilevanti” e che lui come utente ed editor “non era abbastanza autorevole” per modificare quella voce.
A nulla valse il far rilevare che si trattava di se stesso e della propria biografia.
Ecco, il rischio di questo sistema di “verifica della notizia” è in qualche modo quello di creare un “oligopolio” che imporrà “chi e cosa” è rilevante, autorevole, affidabile.
È probabile che sulla singola notizia non saremo d’accordo, ma è anche probabile che la “rilevanza” del sito sia anche dettata da quanto rilevante è quell’editore come inserzionista o come contenitore di pubblicità.
Tag: Google
Google diventa personal stylist: in arrivo la funzione Idee di Stile

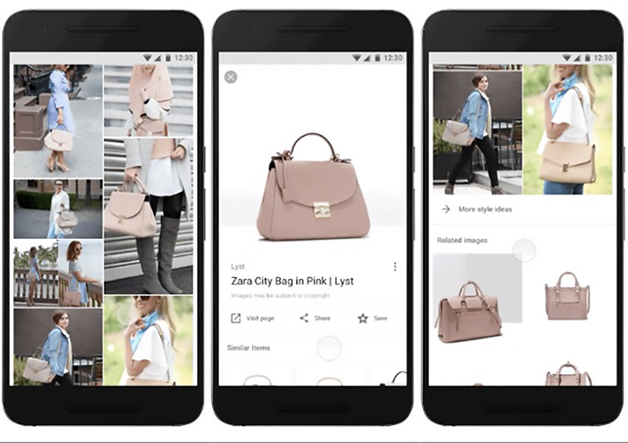
Sui motori di ricerca sempre più spesso le query riguardano abiti, accessori, scarpe e borse, cercate da fan dello shopping online per comparare i prezzi e scegliere il capo perfetto per il proprio guardaroba. Google ha colto questa tendenza e ha deciso di introdurre una nuova funzione: Idee di Stile. La feature, disponibile sull’app Android e iOS, mostra una serie di look in cui sia presente quel capo, per ispirare l’utente e alimentare la sua voglia di shopping. Per esempio, inserendo come parola chiave nella casella di ricerca un capo di un determinato stile, colore o brand (come abito giallo, borsa Louis Vuitton, stivaletti bassi), insieme ai risultati della ricerca apparirà una serie di fotografie di modelle, blogger, adv che inseriscono quel capo in un outfit.
Per Idee di Stile, Google si è ispirato al funzionamento di Pinterest: inserendo una parola chiave, una serie di immagini indica eventuali abbinamenti, look vincenti e capi simili di altri marchi. «Sfogliando le immagini di articoli d’abbigliamento, Google mostra una griglia di outfit e immagini ispiratrici che fanno vedere come un prodotto può essere indossato nella vita reale» spiega la società in un post con cui lancia questa nuova funzione. Il motore di ricerca, capace di cogliere le caratteristiche del capo ricercato e contestualizzarlo nelle immagini di outfit in cui compare, diventa una sorta di personal stylist virtuale. La feature, infatti, alimenta la diffusione di stili e tendenze, convogliando l’attenzione dell’utente verso altri capi e accessori da abbinare e accrescendo così le potenzialità dello shopping online. Non solo: Google Idee di Stile permette anche di visualizzare pezzi simili a quello ricercato, comparando prezzi e brand perché l’utente possa scegliere quello che preferisce tra le tante proposte degli e-commerce. La nuova funzione di Google è stata lanciata il 13 aprile con un post ufficiale, ed è oggi disponibile su iOS e Adroid.
Il British Fashion Council e Google creano l’enciclopedia della moda inglese

Nasce una nuova enciclopedia online per valorizzare l’heritage della moda inglese: l’accordo stipulato tra il British Fashion Council (BFC) e la divisione Arts & Culture di Google intende dare vita ad una nuova eniclopedia digitale (g.co/britishfashion) per salvaguardare il patrimonio della moda made in UK. Il progetto è supportato dalla Education Foundation del BFC e ha l’obiettivo di attrarre i futuri talenti della moda, attraverso l’accesso gratuito a contenuti e storie relative ai più importanti designer inglesi.
Da maison storiche, come Burberry e Vivienne Westwood, a realtà nuove fino a brand che hanno reso l’artigianalità inglese famosa nel mondo, come Harris Tweed Hebrides, John Lobb e la Royal School di Needlework: saranno disponibili alla consultazione oltre mille item, tra cui 20 mostre multimediali, 25 video e tre esperienze di realtà virtuale.
Largo a contenuti video in altissima risoluzione e contenuti multimediali che esplorano lati inediti dei protagonisti della moda inglese, alcuni dei quali sono diretti da Sarah Mower, critico di Vogue America e ambassador del BFC per i talenti emergenti: si tratta di faccia a faccia con protagonisti dell’industria della moda che condividono momenti personali e toccanti della loro carriera. Tramite Google Cardboard e YouTube, gli utenti possono entrare in contatto ravvicinato con Naomi Campbell, con la designer Anya Hindmarch, il direttore creativo Edward Enninful e la fondatrice di Browns, Joan Burstein.

Tante le iniziative lanciate per celebrare la nascita della nuova piattaforma: Paul Smith ha disegnato per l’occasione una speciale edizione di Google Cardboard e creato una mostra online su cinque oggetti rappresentativi del del suo brand.
Il web fragile
Sempre più cloud, intelligenza artificiale, dati salvati online, e le nostre vite legate ad app di acquisto, servizi e pagamenti in tempo reale.
Tutto facilmente accessibile ovunque sia locato fisicamente. Ed aziende con un valore di stima borsistica inimmaginabile per qualsiasi altra tipologia di impresa “che produca beni reali”. Questo è il web, oggi, nel 2016.
Un valore legato ai nostri consumi, ai nostri bisogni, alle nostre informazioni e transazioni. A quello che leggiamo, vediamo, desideriamo, acquistiamo, al dove siamo ed al cosa ci consigliano di fare.
Un mare di informazioni il cui peso in elettroni è stato stimato in qualcosa come meno di 40 grammi, una piccola mela o un paio di fragole.
Questa rete che unisce il mondo e ci consente di guardare televisione, chiamare chiunque da qualsiasi posto, mandare messaggi in almeno venti forme diverse, mandare e ricevere mail con allegati mentre siamo in barca o in macchina, si regge su una infrastruttura reale che conoscono in pochi, e da cui tutto dipende.
Ce ne accorgiamo quando queste reti “vanno giù” ed interrompono i servizi di cui serviamo e con loro le nostre vite. Ce ne occupiamo decisamente poco quando questo patrimonio strategico per il mondo intero oltre ogni classe di confini e interessi particolari, finisce nella mani di qualche azienda (come Verizon e Amazon) che la acquistano per pochi spiccioli mettendosi a patrimonio bande di connessione garantite per i propri beni e servizi e di fatto condizionando – domani – la capacità di accesso di chiunque.
Perché Verizon e Amazon potranno anche “chiudere” il proprio core business, ma “vivranno di rendita” rivendendo la connessione e la banda dati ai propri concorrenti (ed a noi consumatori).
Questa rete così grande è legata attraverso piccoli e grandi nodi. E qualche anno fa era già stato avviato un programma per garantire che se anche una o due dorsali fossero state interrotte, la rete comunque sarebbe rimasta in piedi.
Ieri abbiamo avuto una ulteriore prova di cosa sia il web, della sua fragilità, e di quanto forse non sia un bene che i grandi servizi restino un affare privato che i privati debbano gestire.
Perché se gli utili sono privati, gli interessi sono collettivi, e quelli strategici restano nazionali se non anche geopolitici.
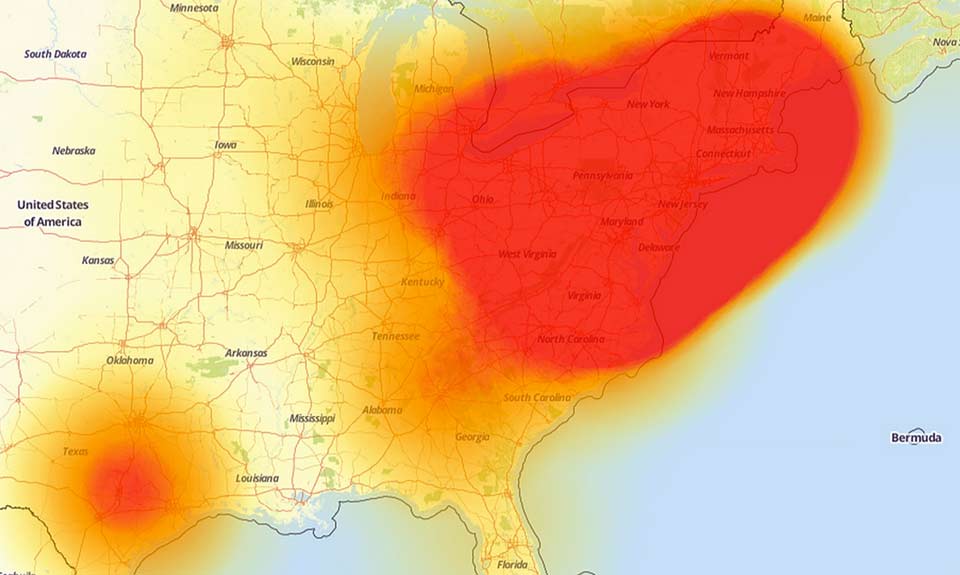
Molto sinteticamente, semplicemente, un attacco massiccio sulla rete Domain Name System service (Dyn Inc), ha letteralmente abbattuto la capacità di connessione della costa est degli Stati Uniti.
L’attacco è stato “semplicemente” un DdoS, ovvero un flusso massiccio di tentativi di connessione (parliamo di decine di milioni di accessi veloci, immediati e simultanei) su uno stesso identico nodo della rete.
Il problema è che su quel nodo e da quel nodo specifico partivano (e arrivavano) gran parte dei servizi di Paypal,Netflix, Github,Twitter, Esty, Pfizer, Visa, Reddit, CNN, FinalcialTimes, NewYork Times, Soundcloud, Spotify, Amazon, Heroku, Shopify, PagerDuty, ZenDesk (la società che gestisce le varie chat automatiche di assistenza clienti su molti siti di servizi), Braintree, Fastly, Cloudflare… solo per citare le più importanti e diffuse.
Il problema pare sia stato risolto in un paio d’ore. Bloccando gli ip di provenienza degli attacchi e contemporaneamente aumentando le risorse di rete, aumentando la capacità di traffico.
Un battito d’ali di farfalla in California che è diventato uno tsunami globale per per tre, quattro ore ha reso non accessibili decine di migliaia di blog, siti, servizi, per decine di milioni di utenti e non possiamo sapere quante vulnerabilità abbia generato.
Kyle York, chief strategy officer della Dyn, ha detto che gli hacker hanno lanciato un attacco denial-of-service distribuito con “decine di milioni” di dispositivi infetti connessi a internet.
Dave Anderson, vice presidente di dynaTrace LLC, società che monitora le prestazioni di siti web, ha dichiarato testualmente “Non ho mai visto un attacco di così vasta gravità, con un impatto su così tanti siti e di così lunga durata. Questo dimostra quanto sia vulnerabile e interconnesso il mondo, e che ormai quando succede qualcosa in una regione, ha un impatto in ogni altra regione.”
Con gli attacchi contro Internet Domain Name System, gli hacker compromettono la tecnologia di base che governa come funziona il web, rendendo l’hack di gran lunga più potente e diffuso.
Il DNS traduce i nomi di siti web in indirizzi Internet Protocol utilizzati dai computer per guardare i siti di accesso. Ma ha un difetto di progettazione: con l’invio di una richiesta di dati di routine a un server DNS da un computer, l’hacker può ingannare il sistema con l’invio di un file che mostra di nuovo gli indirizzi IP al bersaglio. Moltiplicando per decine di migliaia di volte questo processo la mole di dati di cui è inondato il computer bersaglio è enorme.
Un piccolo server può essere in grado di gestire centinaia di richieste simultanee, ma decine di migliaia in un minuto genera un sovraccarico. A quel punto la “macchina” per proteggere se stessa e i dati “si spegne”, e con lei diventano inaccessibili i siti web che ospita online.
Nel caso dell’attacco a Dyn, i computer di destinazione erano i server DNS. Senza server DNS un gran numero di siti web sono inaccessibili dagli utenti di tutto un paese o anche di tutto il mondo. In altre parole, togliendo i server DNS è come togliere tutte le indicazioni sul sistema autostradale di un paese.
William Turton ha commentato “Alcuni pensano che l’attacco sia stato frutto di una cospirazione politica, come un tentativo di abbattere internet in modo che le persone non sarebbero state in grado di leggere i messaggi di posta elettronica della Clinton trapelate su Wikileaks. O per una vendetta per aver chiuso internet ad Assange. Altri pensano che sia il solito assalto russo. Non importa chi l’ha fatto, dovremmo aspettarci incidenti come questo, e che la situazione possa peggiorare in futuro. Stiamo entrando in una nuova era.
Bruce Scheier ha ricollegato questo attacco ad una lunga serie di attacchi “diversi”, che avrebbero tutti insieme una caratteristica comune: sondare la sicurezza della rete nel suo complesso, gli effetti di un attacco e i tempi e i modi di reazione da parte delle compagnie web.
Perché – e questo è un dato che oltre ogni complottismo è più che reale – mettere offline la rete web sarebbe, oggi l’arma perfetta.
E tutto questo – certamente con un focus particolare negli Stati Uniti – non può che far tornare alla mente gli attacchi “dall’estero” al comitato nazionale democratico, alle mail della Clinton, agli attacchi cinesi di spionaggio industriale… al di là delle teorie del complotto è chiaro che – oltre le azioni degli hacktivist – la guerra geopolitica si combatte soprattutto sulle infrastrutture della comunicazione e nel mondo dell’informazione.
Con Tilt Brush, Google manipola “magnificamente” la realtà

Tilt Brush è uno strumento geniale. E’ un oggetto promotore di un’arte nuova.
“Questo non è più disegnare entro i limiti di un foglio, è qualcosa di più simile a scolpire“, ha commentato Glen Kean, animatore di Walt Disney che ha dato i natali a celeberrime storie d’avventura come Tarzan e La Sirenetta.

Con Tilt Brush, il mondo virtuale si fonde con la pittura creando vere opere tridimensionali, visibili attraverso il visore HTC Vive: un casco che permette di interagire con lo spazio attraverso l’ausilio di due joystick.

Lanciato da Google, questo strumento ha davvero dell’eccezionale: “Il vantaggio – dichiara Keane – è che ci si può immergere nello spazio, disegnando in scala reale e muovere attorno alla propria creazione, accettando la nuova sfida di inventare nuove forme di narrazione“.
Un’esperienza sensoriale immersa in una realtà virtuale incredibile.

Sensazioni, peraltro, che si posso avvertire su virtualart.chromeexperiments.com che permette di immergersi in una nuova dimensione e carpire i segreti di questa nuova espressione artistica.
Sei artisti di fama mondiale, Sheryo & Yok (street artist), Christoph Niemann (illustratore), Andrea Blasich (scultore), Katie Rodgers (illustratrice di moda), Harald Belker (designer di automobili) e Seung Yul Oh (creatori di installazioni artistiche), si sono cimentati in questa nuova frontiera espressiva, tastando in esclusiva per il sito, lo strumento.
Fonte cover creativityonline.com
Levi’s e Google: nasce il primo giubbotto smart

Il mondo sarà sempre più connesso grazie a Levi’s Commuter x Jacquard by Google Trucker Jacket, la giacca ideata da Levi’s in collaborazione con Google.
La partnership tra i due colossi americani, che risale al 2015, ha prodotto una giacca che rimane connessa allo smartphone e che consente a chi lo indossa, di poter rispondere alle telefonate, leggere gli sms oppure ricevere indicazioni stradali come un vero navigatore.

Il giubbotto è stato sviluppato da Advanced Technology and Projects (la divisione di Google che si occupa dei progetti più innovativi dell’azienda), mentre il design e i materiali sono stati curati da Levi’s.

Il polsino, è una specie di smartwatch collegato al dispositivo attraverso il Bluetooth. Questa novità, permetterà soprattutto a chi si sposta sulle due ruote, di percorrere le strade in piena sicurezza, evitando distrazioni che potrebbero causare incidenti anche gravi.
Il giubbotto è ancora in fase di perfezionamento e sarà disponibile solo a partire dalla primavera del 2017.
Che cosa sono i malware?

Nella sicurezza informatica il termine malware indica un qualsiasi software creato allo scopo di causare danni a un computer, ai dati degli utenti del computer, o a un sistema informatico su cui viene eseguito. Il termine deriva dalla contrazione delle parole inglesi malicious e software e ha dunque il significato di “programma malvagio”; in italiano è detto anche codice maligno.
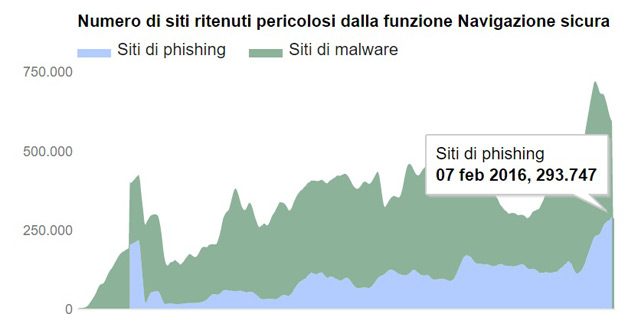
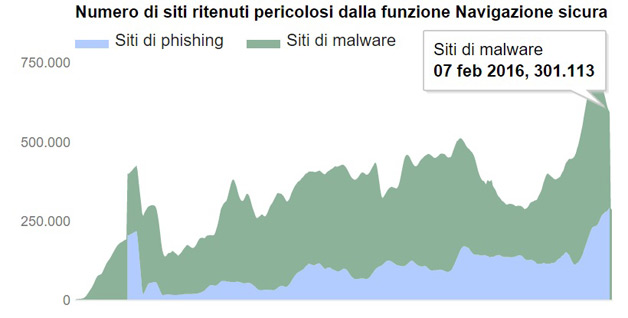
Abbiamo analizzato alcune delle informazioni che Google ha reso disponibili nella sezione navigazione sicura del suo rapporto sulla trasparenza.
La tecnologia navigazione sicura di Google esamina miliardi di URL al giorno alla ricerca di siti web non sicuri molti dei quali sono siti web legittimi che tuttavia sono stati compromessi, ovvero “iniettati” di codice ed usati per diffonderlo.
I siti definiti da Google “non sicuri” rientrano in due categorie che costituiscono entrambe una minaccia per la privacy e la sicurezza degli utenti:
• I siti di malware – contengono codice per l’installazione di software dannoso sui computer degli utenti. Gli hacker possono utilizzare questo software per acquisire e trasmettere informazioni private o riservate degli utenti.
• I siti di phishing – sono apparentemente legittimi ma tentano invece di indurre con l’inganno gli utenti a digitare nome utente e password o a condividere altre informazioni private. Alcuni esempi comuni sono le pagine web che assumono l’identità di siti web di banche o negozi online regolari.
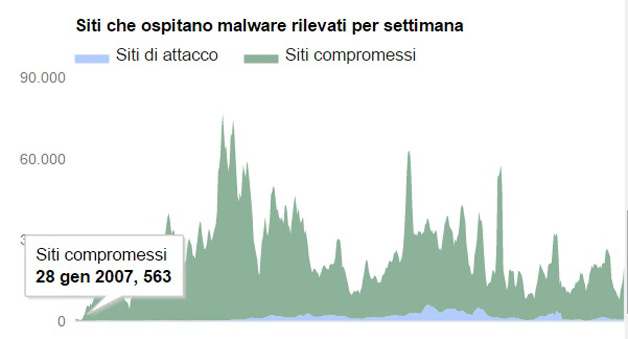
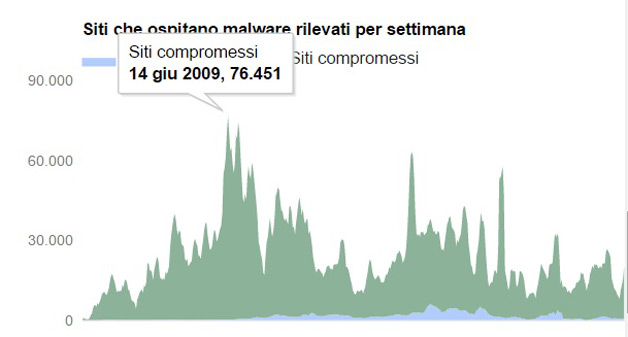
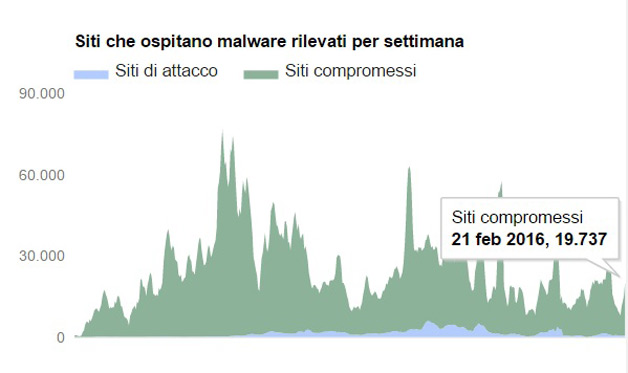
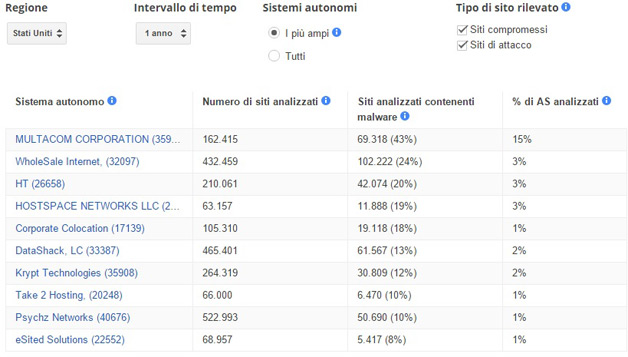
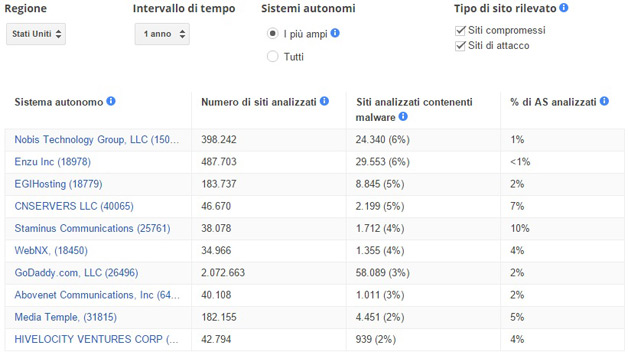
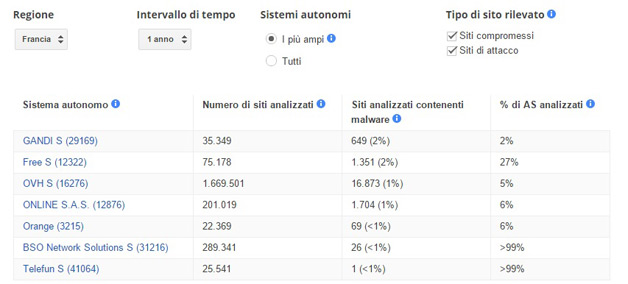
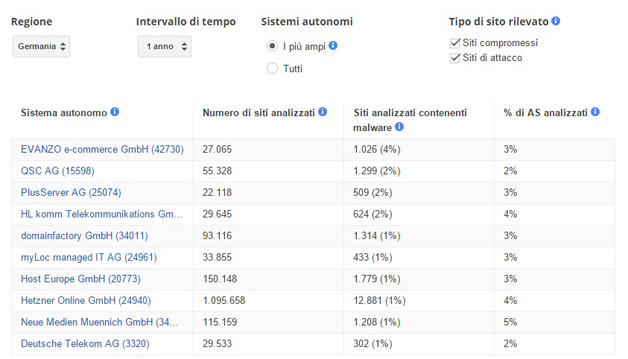
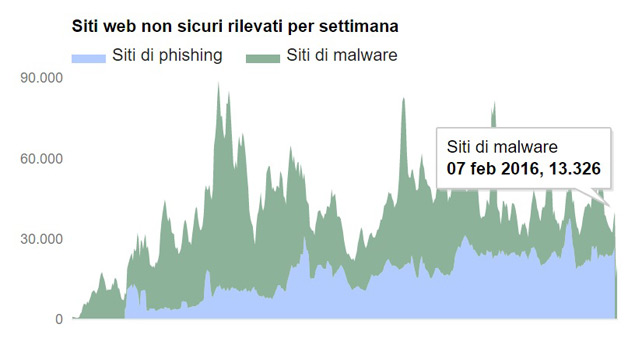
Quasi mezzo milione di siti di malware
Il numero dei siti contenente malware continua a crescere, raggiungendo un nuovo picco di 489.801 nel mese di ottobre del 2015. Una crescita del 160% rispetto allo stesso periodo del 2014.
Un sito web che è stato infettato da malware in grado di installare software dannoso sul computer se lo si visita. Gli aggressori utilizzano spesso il software per rubare informazioni sensibili, come i dati della carta di credito e numeri di previdenza sociale, e le password per accedere a social network e posta elettronica.
In particolare le mail sono importanti perchè spesso – senza rendercene conto – contengono le “recovery”, ovvero il sistema che usiamo quando cambiamo password per molti siti, tra cui conti bancari e paypal.
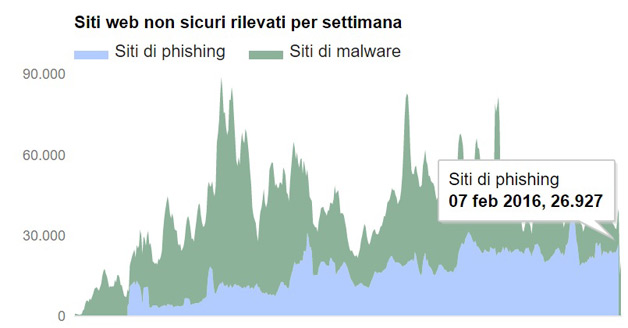
Secondo Google attualmente sono 293,747 i siti di phishing su Internet, rispetto ai 113.132 di luglio dello scorso anno.In questo caso siamo la crescita è del 150% in soli sette mesi.
Un sito di phishing tenta di ingannare l’utente, far credere di essere legittimo, simula la pagina di accesso di una banca, di un sito di ecommerce etc. Attraverso queste schermate, e mail in cui si afferma che l’account è compromesso, o si invita a cambiare password, l’utente fornisce i propri dati, consentendo spesso frodi informatiche diffuse.
Esistono molti sistemi di rilevamento che segnalano quando un sito è stato attaccato, e se contiene malware. Molti di questi tool e widget peraltro sono gratuiti. Sviluppati da e per piattaforme come WordPress e Magento, le più diffuse per siti amatoriali, blog, piccoli siti di ecommerce, e normalmente anche quelli più attaccati perchè spesso sviluppati a livello poco più che amatoriale, e altrettanto spesso allocati su hosting molto economici, senza badare all’acquisto di pacchetti di sicurezza.
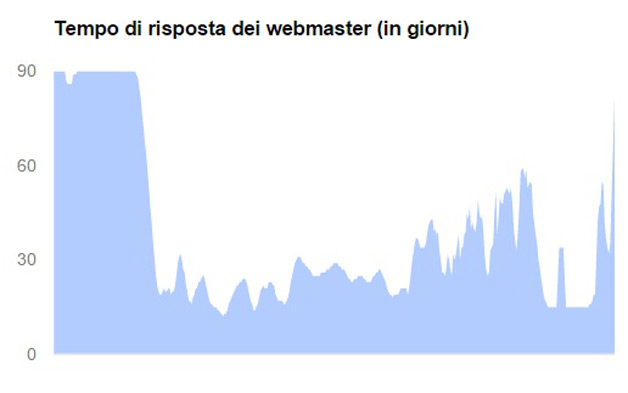
Un dato molto interessante è il tempo di risposta estremamente lenta da parte del gestore/amministratore del sito alla notifica che il suo sito è compromesso. Si arriva anche a tre mesi. Questo periodo non è generalmente dovuto ad apatia, o a scarso interesse, ma da un lungo intervallo di tempo tra quando viene compromesso un sito e il suo rilevamento.
Ma è anche dovuto al fatto che molti pagano siti pensando che poi “facciano tutto da soli” e che un sito sia di per sé sicuro. Molti non considerano la sicurezza una priorità ma un onere. Molto infine dipende dal fatto che spesso i siti vengono creati in modo amatoriale e che i loro creatori – improvvisati deesigner che personalizzano i design di wordpress – non sanno che fare, come risolvere il problema, e non sono disposti a spendere 100 dollari per un software che risolva il problema.
Non a caso il malware – come i virus – è tanto diffuso anche perchè è un business per molte aziende che “curano” il problema, ma anche per i servizi di hosting per vendere pacchetti più costosi, implementazioni, azioni di manutenzione, specie se i siti cominciano ad avere un certo numero di visite.
Tutti questi, e non solo questi, sono i problemi della nuova era del web.
Quando hanno venduto al mondo la necessità di avere tutti un sito, e che questa fosse un’azione facile e gratuita alla portata di tutti. Oggi questo patrimonio di siti web sparsi per il mondo “va messo a reddito” e spesso la diffusione di malware è un modo per vendere servizi aggiuntivi.
La riflessione ovviamente è aperta, e credo che i dati riportati possano offrire ulteriori spunti di riflessione.
Cosa è cambiato nella privacy dell’Unione Europea?
È finalmente disponibile in lingua italiana la bozza del nuovo Regolamento UE Privacy (GDPR) che trovate qui.
L’attuale versione è stata approvata in data 15 dicembre 2015 dal c.d. Trilogo UE e la pubblicazione in Gazzetta Ufficiale Europea è prevista per la primavera, no senza qualche modifica ed integrazione (come desumibile da questa bozza).
Come cambia la normativa, in sostanza?
Molto poco. Più che altro è un tentativo di uniformare le varie regolamentazioni nazionali.
L’esigenza sottostante però è ben più forte.
Sotto la spinta dei casi di intercettazione da parte della NSA, e la rottura di una serie di equilibri primo tra tutti il cd. “Safe harbour” (ovvero quella prassi per cui dati di cittadini europei gestiti da multinazionali americane venivano trasferiti e salvati su server fuori dal territorio europeo).
A tal proposito si segnala ad esempio l’articolo 25 (da leggersi con il successivo art. 40) che parla esplicitamente di Rappresentanti di responsabili del trattamento non stabiliti nell’Unione “… il responsabile del trattamento o l’incaricato del trattamento designa per iscritto un rappresentante nell’Unione…”
In altre parole per uniformare il diritto civile europeo e il suo richiamo alle persone fisiche, in diretta contrapposizione alla prevalente personalità giuridica in capo alle società tipica del diritto americano, potrebbe avvenire che Google debba “fisicamente” indicare un responsabile diretto residente in UE per le policy e il trattamento dati relativo agli utenti Gmail, e che quest’ultimo ne risponda da cittadino europeo secondo le leggi europee dinanzi agli organi richiamati in questo regolamento.
Cui per altro i regolamenti nazionali devono uniformarsi e recepirlo.
Interessante anche l’articolo 55 che prevede una “collaborazione” tra le varie autorità di controllo nazionali. Come previsto nei precedenti articoli esse devono essere “indipendenti” ma anche di nomina governativa (più o meno le nostre Autority) il che però – parlando di dati personali dei cittadini – pone problemi ( e non risolve le attuali aree grigie) ad esempio sui confini tra la collaborazione tra le autority e quella tra servizi di intelligence, anch’esse governative ma indipendenti.
Infine l’articolo 80
Trattamento di dati personali e libertà d’espressione e di informazione
1. Gli Stati membri conciliano con legge il diritto alla protezione dei dati personali ai sensi del presente regolamento e il diritto alla libertà d’espressione e di informazione, incluso il trattamento di dati personali a scopi giornalistici o di espressione accademica, artistica o letteraria.
2. Ai fini del trattamento dei dati personali effettuato a scopi giornalistici o di espressione accademica, artistica o letteraria, gli Stati membri prevedono esenzioni o deroghe rispetto alle disposizioni di cui ai capi II (principi), III (diritti dell’interessato), IV (responsabile del trattamento e incaricato del trattamento), V (trasferimento di dati personali verso paesi terzi o organizzazioni internazionali), VI (autorità di controllo indipendenti), VII (cooperazione e coerenza) e IX (specifiche situazioni di trattamento dei dati) qualora siano necessarie per conciliare il diritto alla protezione dei dati personali e la libertà d’espressione e di informazione.
3. Ogni Stato membro notifica alla Commissione le disposizioni di legge adottate ai sensi del paragrafo 2 e comunica senza ritardo ogni successiva modifica.
Che costituisce – ad esempio – una vera occasione persa per uniformare, almeno in linea generale, i diritti di cronaca, di informazione, e in via indiretta dei principi generali utili alla libertà di stampa e di informazione.
In alcuni Stati la questione si pone poco, legata ad una consolidata (anche laddove spesso discussa) giurisprudenza. Pensiamo a paesi come la Francia, la Germania, l’Olanda, la Danimarca, la Svezia.
Lo stesso non può dirsi di paesi come Ungheria, Polonia, e molti dei paesi di recente ingresso nell’Unione, che spesso non hanno brillato per la tutela del diritto di cronaca, di tutela delle fonti, di libertà di critica e di informazione.
In questo caso non è l’Unione a dare linee guida di tutela minima e principi unici, ma recepisce e prende atto semplicemente delle normative nazionali eventualmente emendate.
Come sempre – e non sono solo questi articoli il caso – pioveranno interpretazioni più o meno estensive di queste norme.
Per questo motivo, prima che venga pubblicato e che diventi vigente, credo che – riguardando tutti noi – sia una cosa utile renderlo disponibile in lettura per farsi un’idea precisa di cosa comporterà questo nuovo regolamento.
Per altro si consideri che dala su entrata in vigore vale anche il principio della regola della “maggiore tutela” ovvero sino al suo recepimento, se un cittadino verrà maggiormente tutelato da questa normativa, si può rivalere riferendosi ad essa contro differenti policy e prassi e regolamenti applicati, ad esempio, dal proprio provider, servizio di posta, compagnia telefonica etc.
Hedy Lamarr: genio e bellezza

Chi tende ancora a sostenere il vecchio e quantomai datato pregiudizio per cui le donne belle non possano brillare anche per intelligenza sarà costretto a ricredersi: la storia ci ha fornito illustri esempi di donne di grande bellezza che, grazie anche al loro carisma e alla loro intelligenza, sono riuscite ad imporsi e spesso a cambiare le sorti della storia.
Un volto splendido e una classe fuori dal comune caratterizzavano Hedy Lamarr, attrice degli anni Quaranta a cui oggi Google dedica il suo Doodle, nel 101/mo anniversario della nascita della diva.
Una bellezza e un’intelligenza fuori dal comune resero Hedy Lamarr una delle attrici più affascinanti del cinema e una delle prime donne al mondo ad imporsi nel settore scientifico. Nata a Vienna il 9 novembre 1914, all’anagrafe Eva Maria Kiesle, nelle sue vene scorreva sangue ungherese ed ucraino.




La conturbante bellezza della giovane impressionò alla fine degli anni Venti il produttore cinematografico Max Reinhardt che la iniziò agli studi cinematografici. Il primo film è Ekstase di Gustav Machaty, girato quando la ragazza ha solo 18 anni. Un film scandalo, a causa di alcune scene a seno nudo, fortemente sensuali per l’epoca.
Nel 1933 la bella attrice sposa il mercante d’armi Friedrich Mandl, che compra quante più copie possibile di quella pellicola. La loro abitazione diviene in breve teatro di numerose feste a cui presero parte, tra gli altri, Adolf Hitler e Benito Mussolini, oltre che diversi esponenti del mondo scientifico, che iniziarono la diva alla passione per le tecnologie. Mandl tuttavia è geloso della sua bellissima moglie e, come lei stessa dichiarò in seguito, tentò di farla vivere segregata. Fu così che, nel 1937, la bella attrice scappò a Parigi. Qui conobbe il produttore cinematografico statunitense Louis B. Mayer, tra i fondatori della casa di produzione cinematografica Metro-Goldwyn-Mayer. Il nome di Hedy Lamarr fu scelto proprio da Mayer, in omaggio a Barbara La Marr, diva del cinema muto.




Nel 1938 Hedy si trasferisce ad Hollywood e qui inizia la sua sfolgorante carriera nel cinema. Prende parte a più di 30 film, tra cui spiccano La febbre del petrolio, dove Hedy recita al fianco di Clark Gable e Spencer Tracy, nel 1940, e Corrispondente X, sempre con Clark Gable, due anni dopo.
Il ruolo forse più celebre fu quello di Dalila nella produzione di Sansone e Dalila di Cecil B. DeMille.



Oltre alla sua straordinaria bellezza e fotogenia, pochi sanno che Hedy Lamarr fu anche una delle prime donne scienziato della storia. Durante la Seconda Guerra mondiale ideò insieme a George Antheil un sofisticato sistema per realizzare messaggi criptati via radio, affinché non potessero essere intercettati. Il prototipo, basato sul meccanismo del pianoforte, fu brevettato nel 1942 e fu utilizzato per la prima volta circa venti anni più tardi dalla marina militare degli Stati Uniti. La diva fu inserita nella Inventors Hall of Fame degli Stati Uniti nel 2014 per questa sua invenzione, che è ancora oggi alla base di molti sistemi tecnologici nonché della telefonia mobile.
Inoltre Hedy Lamarr brevettò anche altre invenzioni, tra cui una compressa per ideare bibite gasate ante litteram e un ingegnoso prototipo di semaforo per regolare il traffico cittadino. La sua lunga carriera cinematografica negli anni Settanta era ormai agli sgoccioli: dopo il ritiro dalla vita pubblica, nel 1981, la diva appariva ossessionata dalla chirurgia estetica. Hedy Lamarr morì il 19 gennaio del 2000, all’età di 85 anni, e le sue ceneri furono disperse nella Selva Viennese.
Potrebbe interessarti anche:
È iniziata la Milano Vintage Week
Web privacy e diritto all’oblio

Se lo affrontiamo da un punto di vista tecnico e giuridico, il “diritto all’oblio” è il diritto riconosciuto ad una persona a non restare indeterminatamente esposti ai danni ulteriori che la reiterata pubblicazione di una notizia può arrecare all’onore e alla reputazione, salvo che, per eventi sopravvenuti, il fatto precedente ritorni di attualità e rinasca un nuovo interesse pubblico all’informazione; è una parte essenziale della declinazione concettuale del cd. “diritto alla privacy”, che appunto non è più solo il diritto che alcune informazioni individuali siano o meno rese note, ma soprattutto il riconoscimento della “disponibilità” personale di quelle informazioni, che possono essere divulgate solo con consenso esplicito.
Una sfera molto delicata di applicazione è nel diritto di cronaca, e anche più quando si parla di diritto all’oblio che parte dal presupposto che, quando un determinato fatto è stato assimilato e conosciuto da un’intera comunità, cessa di essere utile per l’interesse pubblico: smette di essere quindi oggetto di cronaca e ritorna ad essere fatto privato. Questo diritto difende indirettamente anche le vittime, in quanto ogni volta che un caso viene rievocato finisce per pesare di riflesso su chi lo ha subito nel ruolo di parte lesa (si pensi al caso delle violenze sessuali).
Il tema è di sempre maggiore attualità nell’era digitale, in cui le informazioni sono online, senza filtri, senza alcuna possibilità di controllo della loro attendibilità, veridicità, e tecnicamente rese “immortali” dalla assenza di procedure o prassi idonee a dare una “scadenza” alla permanenza dei dati. Si configura sempre più spesso la rivendicazione di un “diritto ad essere dimenticati online” inteso come la possibilità di cancellare, anche a distanza di anni, dagli archivi online, il materiale che può risultare sconveniente e dannoso per soggetti che sono stati protagonisti in passato di fatti di cronaca. L’estensione del diritto all’oblio al mondo del web si è rivelata un’operazione più difficile del previsto, fonte di dibattiti e controversie.
Il tema torna di attualità oggi con una sentenza della Corte di giustizia dell’Unione europea. In un pronunciamento consultivo su un caso spagnolo, la Corte afferma che Google e altri motori di ricerca hanno il controllo dei dati privati individuali dal momento che talvolta raccolgono e presentano i link in modo sistematico; l’azienda aveva sostenuto invece che non controlla i dati personali e si limita ad offrire link a informazioni già disponibili su internet gratuitamente e legalmente, sostenendo che non dovrebbe essere costretta ad assumere il ruolo di censore.
Per la Corte in base alla legge europea le persone hanno il diritto di controllare i propri dati privati, specialmente se non sono personaggi pubblici. Se vogliono che informazioni personali irrilevanti o sbagliate su di loro vengano «dimenticate» dai risultati dei motori di ricerca, hanno il diritto di chiederne la rimozione anche si tratta di informazioni pubblicate legalmente. Se la richiesta venga accettata o meno dipenderà «dalla natura delle informazioni in questione, dalla sensibilità per la vita privata del titolare dei dati e dall’interesse pubblico dei dati stessi, interesse che può variare».
Google, afferma la Corte, deve rimuovere dai risultati i link «a meno che non ci siano particolari ragioni, come il ruolo giocato dal titolare dei dati nella vita pubblica, qualora sia tale da giustificare un interesse preponderante dell’opinione pubblica nell’avere accesso a quelle informazioni quando viene fatta la ricerca». Se lo spirito della sentenza appare corretto e chiaro, lo è meno nella sua applicazione concreta, che come spesso accade individua nel gestore informatico di un servizio anche una sorta di “arbitro umano” nella selezione e gestione delle informazioni, cui piacerebbe delegare giudizi di merito e caso per caso, cosa letteralmente impossibile nel web.
Semmai sarebbe utile “usare” Google per ottenere quali siano i siti da contattare e rivolgersi direttamente a quelli per la modifica delle informazioni ritenute lesive.
Ma la sentenza non tocca i punti sensibili della gestione delle informazioni soggette al diritto all’oblio sui cui nessun legislatore ha mai indicato strumenti chiari che diano la certezza che banche dati private (quelle che vendono informazioni ad esempio a istituti di credito, finanziarie, assicurazioni) cancellino effettivamente a scadenza le informazioni “oblate”. Anzi, quanto più profonde e storiche sono le informazioni tanto più hanno valore economico, anche se riferite a atti o fatti storici da cancellare, come protesti, insolvenze o malattie croniche di dieci o vent’anni prima completamente curate, o carichi pendenti per i quali sia stata disposta anche la non menzione nei casellari giudiziari.